

【模拟】多个数组求交集
题目
给你一个二维整数数组 nums ,其中 nums[i] 是由 不同 正整数组成的一个非空数组,按 升序排列 返回一个数组,数组中的每个元素在 nums 所有数组 中都出现过。
示例 1:
| |
示例 2:
| |
提示:
1 <= nums.length <= 10001 <= sum(nums[i].length) <= 10001 <= nums[i][j] <= 1000nums[i]中的所有值 互不相同
解题思路
定义一个map,统计每个数出现的次数,最后判断是否为n即可
map会自动排序
代码
| |
【枚举】统计圆内格点数目
题目
给你一个二维整数数组 circles ,其中 circles[i] = [xi, yi, ri] 表示网格上圆心为 (xi, yi) 且半径为 ri 的第 i 个圆,返回出现在 至少一个 圆内的 格点数目 。
注意:
- 格点 是指整数坐标对应的点。
- 圆周上的点 也被视为出现在圆内的点。
示例 1:
| |
示例 2:
| |
提示:
1 <= circles.length <= 200circles[i].length == 31 <= xi, yi <= 1001 <= ri <= min(xi, yi)
解题思路
很难受啊,这题TLE了一发
看数据规模是妥妥的暴力,没想到竟然TLE了,一开始是枚举200*200个点,再在最多200个圆里判断是否出现在其中,TLE了
然后换了个遍历的思路,先枚举圆,再统计该圆覆盖的格点数目,最后再统计200*200个格点,看出现次数是否大于0,A了
结束后,发现其实两种思路都能过的,毕竟数据范围就10^6,第一次TLE的原因是auto没加引用
也就是说,以后用auto,能加引用就加,速度会快一点
代码
| |
| |
【枚举+二分】统计包含每个点的矩形数目
题目
给你一个二维整数数组 rectangles ,其中 rectangles[i] = [li, hi] 表示第 i 个矩形长为 li 高为 hi 。给你一个二维整数数组 points ,其中 points[j] = [xj, yj] 是坐标为 (xj, yj) 的一个点。
第 i 个矩形的 左下角 在 (0, 0) 处,右上角 在 (li, hi) 。
请你返回一个整数数组 count ,长度为 points.length,其中 count[j]是 包含 第 j 个点的矩形数目。
如果 0 <= xj <= li 且 0 <= yj <= hi ,那么我们说第 i 个矩形包含第 j 个点。如果一个点刚好在矩形的 边上 ,这个点也被视为被矩形包含。
示例 1:
| |
示例 2:
| |
提示:
1 <= rectangles.length, points.length <= 5 * 10^4rectangles[i].length == points[j].length == 21 <= li, xj <= 10^91 <= hi, yj <= 100- 所有
rectangles互不相同 。 - 所有
points互不相同 。
解题思路
打比赛的时候一直在搞怎么排序好,但排完后也没想好接着怎么做
注意数据范围,宽的范围是10^9,而高的范围是100。
按高存储不同矩形,当高相同时,将宽按从小到大排序
遍历点时,统计高度在[1,100]范围内,用二分计算每个高度合法的矩形数量
代码
| |
【差分、线段树等】花期内花的数目
题目
给你一个下标从 0 开始的二维整数数组 flowers ,其中 flowers[i] = [starti, endi] 表示第 i 朵花的 花期 从 starti 到 endi (都 包含)。同时给你一个下标从 0 开始大小为 n 的整数数组 persons ,persons[i] 是第 i 个人来看花的时间。
请你返回一个大小为 n 的整数数组 answer ,其中 answer[i]是第 i 个人到达时在花期内花的 数目 。
示例 1:
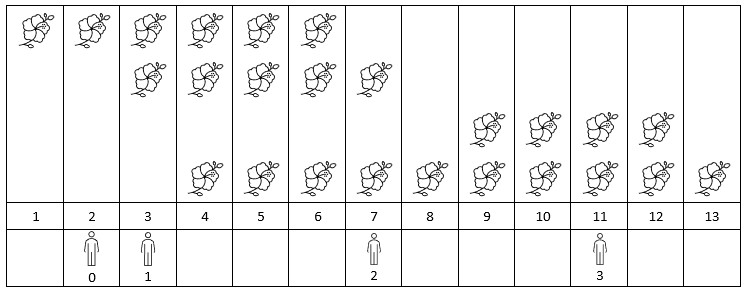
| |
示例 2:
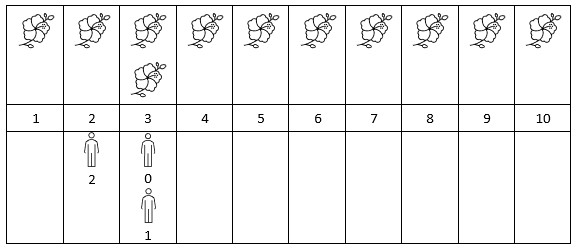
| |
提示:
1 <= flowers.length <= 5 * 10^4flowers[i].length == 21 <= starti <= endi <= 10^91 <= persons.length <= 5 * 10^41 <= persons[i] <= 10^9
排序+二分
正在开的花的个数 为所有在此时间节点及之前开放的花的个数减去在时间节点之前凋谢的花的个数
先分别存下花期的开始时间和结束时间,排序
然后二分查找满足条件的花
| |
差分
把flowers[i]分成两个点:(flowers[i][0],-INF)表示花期的开始,(flowers[i][1],INF)表示花期的结束,每个询问看成一个点(person[i],i)
这样做是为了方便排序。维护变量now,表示花的变化量,遇到花期开始则now++,遇到花期结束则now–,询问答案就是当前now值
代码:
| |
动态开点线段树
记录在力扣题解上:
代码:
| |
离散化+线段树
还可以利用离散化+线段树,它们的目的都是尽量减少所需要的节点数目。
虽然时间值域很大,达$10^9$,但是注意到花期+每个人的到达时间 总共的时间数量不超过 $2\times 5e4 + 5e4$,所以可以进行离散化,*将所有时间放在一起排序后,用它们在数组中的索引来代替原来的值即可*。
然后可以进行去重,除掉重复的元素。
有个细节是实现的线段树节点编号是以1开始索引的,所以后面使用区间范围时要+1(不然是0开始)
代码:
| |